Clearly it’s not the case that “if we build it, they will come”. How then might we fill them?
Problem
What we’ve tried (that hasn’t been enough):
[specialized [curator] model of semantic publishing]
accurate but has serious sustainability issues
[text mining model of semantic publishing]
cheap but inaccurate (horizon still quite far off)
though in conjunction with human labor might be good
We’re exploring the [scholar-powered model of semantic publishing]
In this talk our goal is to show you a new/untapped opportunity for a kind of [scholar-powered model of semantic publishing] - specifically, we’re going to show
What, if any, existing [standards] and conceptual models could be suitable for gluing these individual practices to a collaborative context in a way that enables [interoperability]?
P3 from John Thesis: rich summary of papers with many details that are useful for the current context, but maybe not as useful for others
WW from #@qianOpeningBlackBox2020: summaries of papers, with many links to related ideas as context, snapshots of key figures / details from text
NB from #@qianOpeningBlackBox2020: structured summaries for papers / books to be read in detail. Includes summaries of “main points”, but also important details and evidence, and notes about what aligns or conflicts
P5 from John Thesis extract segments and relate to them in “typed” ways (but not formally) on a canvas, such as “perspectives from…”
Note: each of these excerpts have rich mechanisms for context, e.g., connecting to other pieces (because they are “disembedded”), “transclude” in new contexts, in addition to auto signals to name of pdf, page number, and quick jump back to original location of excerpt. Same with the QDAS route.
P1 from John Thesis: “code” excerpts from papers, place in code tree
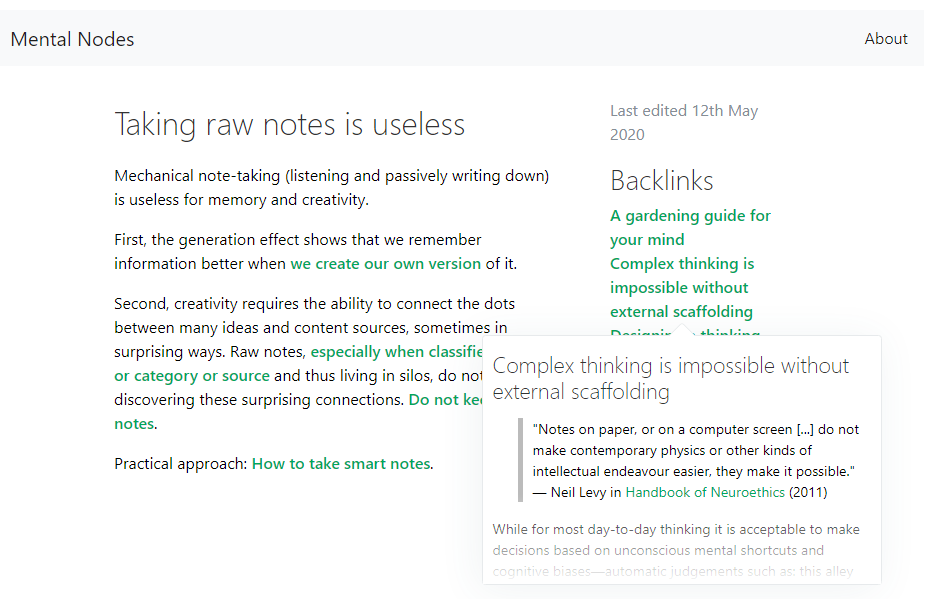
Another good example of the hacker persona is [Ian Jones]’s [Digital Garden].
Ian isn’t an actively practicing scientist: he’s primarily a software developer by trade, but he works with egghead.io (with Maggie Appleton) on creating effective programming-related explainers and tutorials. So he is essentially a learning scientist in practice.
A key feature that he tries to accomplish is [composability] through linking, a la Zettelkasten. This method of composability partially relies on effective [compression] of ideas into relatively atomic notes about key ideas, that he can then densely link with others. This partially achieves [contextualizability] as well.
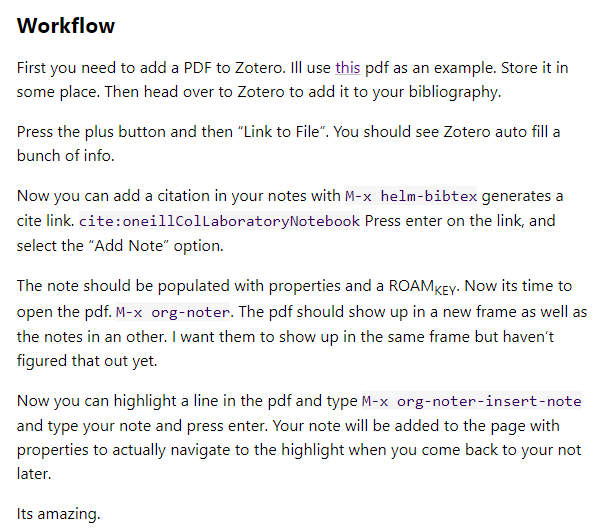
What I want to highlight, though, is a hack that he made to provide richer [context]ualizability] links back to original sources, using org-mode extension that can connect specific excerpts from PDFs to notes - each note then becomes a “pointer” back to a specific segment in the PDF.
Another example of a hacker persona (who may not personally have deep development knowledge, but can team up well with those who do) is Anne-Laure Le Cunff’s [Digital Garden]
Built on top of TiddlyWiki, and inspired by Andy Matuschak’s approach, she also employs compression to enable richer [[contextualizability]] through bi-directional links. This particular instance, though, has less connection to primary/original sources, which is fairly typical of many of the Digital Gardens at play right now.
Stian Håklev is another example: back in his PhD, he created a personal wiki to enable tighter integration between his ideas and his sources (strongly motivated by desire for [[contextualizability]])
GlamorousToolkit - not purpose-built for synthesis, but very easy to do it in here, with huge advantages for Multiplicity due to its superior programmability
privacy, sustainability (not just the “next hot tool”), being “future proof” (is a big reason to work in plain text, in emacs or Markdown)
Other notes
Many are not scholars, but some are! Especially as the line between explorers and hackers blurs with the advent of more “plugin-friendly” systems like Obsidian and Roam Research (in the latter, you can now write simple javascript to augment the experience; have personal experience of a law professor writing some simple javascript to visually, with some minimal semantics, distinguish source excerpts from his own thoughts)
see Trick: use embedded JS to modify the DOM based on tags to make visual distinctions between my thoughts and others’ thoughts. from Roaman lit-reviewing meetup June 5th, 2020
Can see these as instances of end-user programming, probably not too far from the zone of proximal development for many of these researchers, especially as the lines between “technical/programming” work (e.g., move from SPSS to R) become blurred
As norms move towards more open science, open data, digital-based workflows, and so on, there is significant opportunity to integrate with these favorable trends to explore how semantic publishing standards might be better integrated into scholarly workflows
Hackers are important because they can create a more open ecosystem of tools (cf. Athens, FoamBubble, Obsidian) that are easier to try. This broadens the base beyond those who are tied to a particular platform or price point.
Important to be clear about what precisely we mean by semantic publishing: uptake of what by whom, where
Referring to: Yet, on the whole, we’re not seeing nearly as much of this transformation as we’d like. Uptake of semantic publishing is low and restricted to a small set of power users
“In the present context, I define ‘semantic publishing’ as ^^anything that enhances the meaning of a published journal article, facilitates its automated discovery, enables its linking to semantically related articles, provides access to data within the article in actionable form, or facilitates integration of data between papers^^. Among other things, it involves enriching the article with appropriate metadata that are amenable to automated processing and analysis, allowing enhanced verifiability of published information and providing the capacity for automated discovery and summarization. These semantic enhancements increase the intrinsic value of journal articles, by increasing the ease by which information, understanding and knowledge can be extracted. They also enable the development of secondary services that can integrate information between such enhanced articles, providing additional business opportunities for the publishers involved. Equally importantly, readers benefit from more rapid, more convenient and more complete access to reliable information”
Historically the focus of your work on data modeling has been on the practice of a community, or in the practice of specialized curators. Here we’re focusing on what that might look like in the practice of an individual scholar.
As we studied and built stuff, we started to notice a pattern of needs emerging, in terms of “what’s missing”: these 3/4 things (Compression, Context, Composability, etc.)
This pattern of needs is quite similar to the requirements/motivations of a BUNCH of data models that have been developed already by your community, for alternative infrastructures for synthesis.
Discussing “where we are” in the infrastructure (note that standards are probably ok, tooling is not) is helpful, and thinking through the challenges in the other parts of the infrastructure will yield generative conversations
Renewed charge to build a semantic knowledge layer, dating back to Semantic Web, Hypertext, etc., but refined with recent advances in infrastructure studies and reuse, and experiences with trying to build these layers, including the thread on Claims within HCI
important to think through more carefully why Xanadu and the many Semantic Web and Hypertext or Memex related projects have “failed”.
More interesting: subtleties, nuances of the elements of the framework
What do we already know (lit-wise) about the rubber meeting the road?
#@kuhnBroadeningScopeNanopublications2013 has a user study that checks how easy it is to train 16 biomed researchers to convert a short text into a natural language statement (no formality though!)
POtential new data sources for our observations / anecdotes to add the “road” to the rubber
Found old thread of video recordings on my Youtube channel taht really nicely track the evolution (and constancy) of our ideas around #Synthesis Infrastructure!
Reading again the CEDAR project: motivation and lessons are similar for open data: everyone knows science is better for it if data are shared with appropriate metadata, following FAIR principles. But uptake is low, except when there are extreme incentives. Some stuff I saw at iConference last year along this vein. See also @tenopirDataSharingScientists2011
➰ breadcrumbs
For “data collection” (FOCUS ON THIS FIRST)
- {{DONE}} Begin compiling a “results” section.
- For this: So far, we’re seeing that a surprising amount of that labor is already happening! Completely of their own volition, away from any data models people, real scholars are trying to shape their workflows / setups to satisfy requirements of compression / context / composability / multiplicity.
- Maybe start with something high level like
- “How are scholars doing “semantic publishing”-like labor in their synthesis practice?” #[[Z]]
For motivation / framing
- {{DONE}} Read and zettel a few seed papers on “uptake” of specifically “semantic publishing” for scholarly work
- Seed is @kuhnNanopublicationsGrowingResource2018 reports around 10 million Nanopublications published at the time of writing, albeit almost all within bioinformatics, and overwhelmingly dominated by a small (N=41!!) set of authors
- {{DONE}} Start a thread collecting state of the art on text mining for semantic publishing
- Seed is #@kilicogluBiomedicalTextMining2017
We resonate a lot with the vision cast by #@renearStrategicReadingOntologies2009: “Scientists will still read narrative prose, even as text mining and automated processing become common; however, these reading practices will become increasingly strategic, supported by enhanced literature and ontology-aware tools. As part of the publishing workflow, scientific terminology will be indexed routinely against rich ontologies. More importantly, formalized assertions, perhaps maintained in specialized ‘structured abstracts’ (27), wil provide indexing and browsing tools with computational access to causal and ontological relationships. Hypertext linking will be extensive, generated both automatically and by readers providing commentary on blogs and through shared annotation databases. At the same time, more tools for enhanced searching, scanning and analyzing will appear and exploit the increasingly rich layer of indexing, linking, and annotation information.” (p. 832)
It’s not that we have made no progress! Indeed, the semantic publishing revolution is indeed underway! We see encouraging developments, in bioinformatics and archeology, for example.
Yet, on the whole, we’re not seeing nearly as much of this transformation as we’d like. Uptake of semantic publishing is low and restricted to a small set of power users
For example, Genuine semantic publishing notes, “It turns out that all the technologies needed for applying genuine semantic publishing are already available and most of them are very mature and reliable. There are no technical obstacles preventing us from releasing our results from today on as genuine semantic publications, even though more work is needed on ontologies that cover all relevant aspects and areas and on nice and intuitive end-user interfaces to make this process as easy as possible.” (p. 148)
The [[specialized curator model of semantic publishing]] is currently the engine of what uptake exists. But it requires a lot of funding, for a really long time! It’s a great fit for well-funded domains like biomedical sciences, but is a much harder sell for many other domains of knowledge with less obvious funding implications, like the humanities and social sciences. And it’s hard to predict in advance precisely which fields are going to be “worth funding”: knowledge doesn’t work that way!
We think this is a promising approach! There is potential alignment of incentives, with semantic publishing providing high potential payoffs in visibility and impact of work. But we’re unsure
In our work, ^^we are exploring the potential of addressing the authoring bottleneck by integrating into the work that scholars are already doing^^, as a replacement/supplement to text mining and specialized labor.
Revealing these “integration points” would help us see where we might be able to “accrete” semantic authoring tools to leverage the rich semantic work that is already happening.
Investigating these integration points could also help us understand how to better design “intuitive user interfaces” for authoring tools: beyond “usability”, we could improve sustainability by improving, rather than disrupting, existing scholarly workflows
At the same time, we could help address incentive mismatches if these integration points allow us to also significantly augment individual synthesis so that the labor of semantic publishing yields more immediate benefits.
So far, we’re seeing that a surprising amount of that labor is already happening! Completely of their own volition, away from any data models people, real scholars are trying to shape their workflows / setups to satisfy requirements of compression / context / composability / multiplicity.
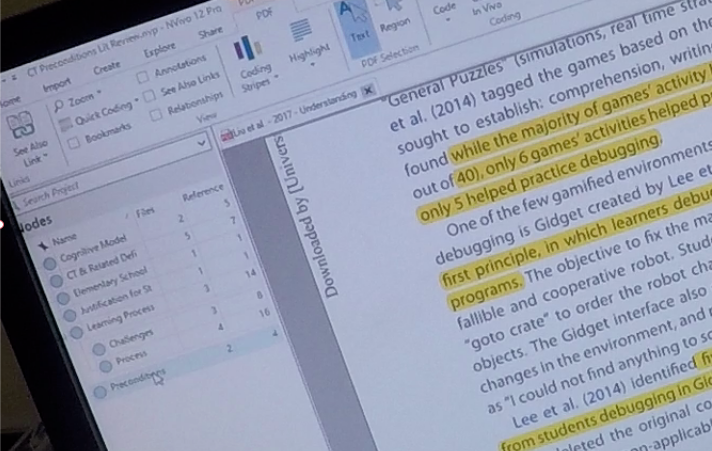
Achieve compression more explicitly, creating excerpts that are manipulable by themselves, but also make sure they’re typed composability and have particular semantically meaningful relationships to other compressed segments (composability). A TON of context you get for free: no need to do the tedious manual work of writing down a source name and page number. Can see this as a next-level evolution of the practice of highlighting that we’ve seen.
Note: this is interesting because LiquidText explicitly builds on the deep work in active reading
Examples
P1 from John Thesis: “code” excerpts from papers, place in code tree
P5 from John Thesis extract segments and relate to them in “typed” ways (but not formally) on a canvas, such as “perspectives from…”
Note: each of these excerpts have rich mechanisms for context, e.g., connecting to other pieces (because they are “disembedded”), “transclude” in new contexts, in addition to auto signals to name of pdf, page number, and quick jump back to original location of excerpt. Same with the QDAS route.
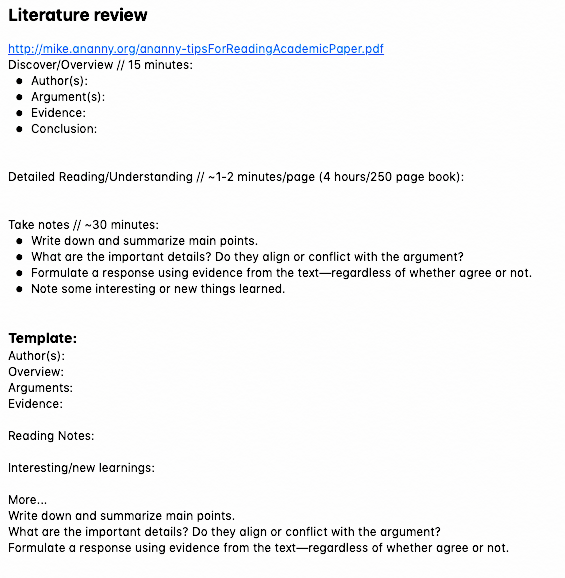
^^Rich TL;DRs^^
Summary
Includes summaries of main claims (compression) and how they relate to each other composability, as well as key details (context) to be used
This recalls some practices that others also do, see, e.g., memorandums, as described and popularized by Raul Pacheco-Vega
NB from #@qianOpeningBlackBox2020: structured summaries for papers / books to be read in detail. Includes summaries of “main points”, but also important details and evidence, and notes about what aligns or conflicts
WW from #@qianOpeningBlackBox2020: summaries of papers, with many links to related ideas as context, snapshots of key figures / details from text
P3 from John Thesis: rich summary of papers with many details that are useful for the current context, but maybe not as useful for others
The conceptual and technical roots of this wave can be traced to the influential ideas of Vannevar Bush, Ted Nelson, and Doug Engelbart around Hypertext. This scene has also been heavily influenced by the idea of a Zettelkasten approach for Knowledge Management, originated in Niklas Luhmann, and later popularized in the English-speaking world by zettelkasten.de, Sönke Ahrens with @ahrensHowTakeSmart2017, and, most recently, beginning approximately in 2019, by the emergence of Roam Research. There is also substantial influence from @andy_matuschak, an independent researcher in the US Bay Area, who has put forward the concept of Evergreen Notes, and was one of the first to start sharing his. Andy himself is better understood as one of the Hackers, as we will discuss in more detail.
The key practices and affordances of hypertext notebooks focus on the creation and maintenance of relatively atomic notes (either a concept or some kind of focused “claim”) that are densely linked together. The links are typically accomplished through bi-directional links, where, every time a link is made from one source note to a target note, both the source and target notes record the link. In this way, links between notes are more accessible, since links can be followed from either source or target notes.
bi-directional links are a key innovation on top of the original Wiki approach, because they enables more focused usage and labor around tending to connections between notes (composability). The links also enable compression by supporting refactoring of ideas into smaller pieces, knowing that you will still be able to follow threads of logic: users can compress quite complex ideas into a single statement (e.g., “knowledge is contextual”) while retaining links to the less compressed ideas that “unpack” different aspects and subtleties of the more complex idea. In this way, tending to the notes and links also enhances the [[contextualizability]] of each note.
The system emphasizes separation between “your thoughts” (the main content of these networked notebooks) and “others’ thoughts” (which should live in “literature notes” that are linked to, but separated from, the networked notebook) The atomicity of the notes is a way to achieve compression, both obviously (by breaking things down), but also in more subtle ways, by compressing quite complex ideas into a single statement (e.g., “knowledge is contextual”) while retaining links to the less compressed ideas that “unpack” the complex idea.
The atomicity and bi-directional links also emphasize the deliberate practice of composability: developing ideas into more complex and better forms over a long period of time. The phrase “finding connections” is a staple in this community.
Since notes that collect bi-directional links can be as “small” as a single concept, the act of deliberately linking notes partially accomplishes the work of deliberately developing folksonomies, which approximate the more formal / ontologies work of semantic publishing for composability. A key affordance in these hypertext notebooks is that it is quite easy to rename note titles — changes to a note’s title typically automateically propagate throughout the database of notes — which enables more agile and evolving ontologies.
People in the Hackers community are actively working on ways to manage aliases and merging.
Many of these in isolation are not new! Lots of beautifully detailed work in active reading; see as far back as #@oharaStudentReadersUse1998 for rich examples, or even… as far back as Charles Darwin and, arguably, as old as external representations ;). What we see here is a different lens with which to view these data, to consider what these behaviors (could) do.
They want to do this work (better), but often don’t because it ends up being too costly
But the social context is key for at least some of it: a lot of explicit work being done in collaborative settings
Advisor meetings
Large-scale collaborations
Teams
Strong opportunity for progress by partnering modeling and standards work with growing user interface innovations (sort of the reverse of making semantic publishing user interfaces better).
which types of annnotations at which points might be valuable for the user to formalize / contextualize in some way?
how might formalisms of semantic publishing deliver immediate value to the scholar at different parts of their scholarly workflow?
identify some of the frictions and pain points in their process. good clue to this is what motivates the move to QDAS and LiquidText - quotes from guided tour in John Thesis?
how much of this is actually happening? is there a way to study this in a way that is analogous to the cognitive surplus idea from crowdsourcing?
see, e.g., What is the scale at which scientists are producing annotations and notes? In other words, what is the untapped opportunity here? What is the “drag coefficient”? How much energy is being “wasted’?